U8G2之自定义中文字库

技术经验 • dingxiao • 阅读数:8690 • 2019年8月18日 13:18

U8G2之自定义中文字库
0x01-U8G2中文字库
0x02-参考文章
生成自定义中文字库参考网址:
1)https://unordered.org/timelines/59d6834747801000 --最终参考该篇才解决
2)https://blog.csdn.net/whynotic/article/details/45097369
3)https://blog.csdn.net/fengyu09/article/details/50408780
4)https://github.com/larryli/u8g2_wqy/wiki --guihub中文移植库
0x03-在线工具
在线可使用的工具,分别是Unicode code converter和Image to bitmap array。
https://r12a.github.io/app-conversion/ --Unicode code converter
https://tools.clz.me/ --Image to bitmap array
根据https://unordered.org/timelines/59d6834747801000介绍的方法,他是采用替换u8g2原有“u8g2_font_unifont_t_chinese1数组中的内容的方法。他的描述是:
从这个命令我们可以知道map文件是 “chinese1.map”,全路径是:“u8g2\tools\font\build”,我们可以在“chinese1.map”文件里面添加我们要显示的中文。生产的字库代码在u8g2_font_unifont_zgzt.c里面,我们可以拷贝里面的内容,然后把它替换" U8g2\src\clib\u8g2_fonts.c " 里面的数组“u8g2_font_unifont_t_chinese1”的内容。

自己尝试了一下,觉得有些不妥,不过可用,需要找到更好的方法。
0x04-自我实践之路
我采取的方法是使用u8g2自带的工具进行自定义中文库的生成,u8g2制作字库工具的目录为:
u8g2\tools\font\bdfconv
bdfconv.exe这个工具是一个dos命令,需要开启cmd.exe在命令行输入命令或者用bat脚本来生成字库。bdfconv.exe命令的使用方法如下:
bdfconv.exe这个工具是一个dos命令,需要开启cmd.exe在命令行输入命令或者用bat脚本来生成字库。bdfconv.exe命令的使用方法如下:
bdfconv [options] filename-h Display this help-v Print log messages-b <n> Font build mode, 0: proportional, 1: common height, 2: monospace, 3: multiple of 8-f <n> Font format, 0: ucglib font, 1: u8g2 font, 2: u8g2 uncompressed 8x8 font (enforces -b 3)-m 'map' Unicode ASCII mapping-M 'mapfile' Read Unicode ASCII mapping from file 'mapname'-o <file> C output file-n <name> C indentifier (font name)-d <file> Overview picture: Enable generation of bdf.tga and assign BDF font <file> for description-l <margin> Overview picture: Set left margin-a Overview picture: Additional font information (background, orange&blue dot)-t Overview picture: Test string (Woven silk pyjamas exchanged for blue quartz.)-r Runtime testmap := <mapcmd> { "," <mapcmd> }mapcmd := <default> | <maprange> | <exclude>default := "*"maprange := <range> [ ">" <addexpr> ] Move specified glyph <range> to target code <num>exclude := "~" <range>range := <addexpr> [ "-" <addexpr> ] Select glyphs within specified rangeaddexpr := <mulexpr> [ "+" <mulexpr> ]mulexpr := <num> [ "*" <num> ]num := <hexnum> | <decnum>hexnum := "$" <hexdigit> { <hexdigit> }decnum := <decdigit> { <decdigit> }decdigit := "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"hexdigit := "a" | "b" | "c" | "d" | "e" | "f" | "A" | "B" | "C" | "D" | "E" | "F" | <decdigit>{ } zero, one ore more, [ ] zero or once, | alternativeexample: -m '32-255' select gylphs from encoding 32 to 255 -m '32-255,~64' select gylphs from encoding 32 to 255, exclude '@' -m '32,48-57' select space, '1', '2', ... '9'build modes: -b 0: Most compact, glyph bitmap is minimal -b 1: Like -b 0, but glyph bitmap is extended to the height of the largest glyph within the selected glyph list. Also the width of the gylphs is extended to cover the delta x advance. -b 2: Like -b 1, but glyph width is set to the width of the largest glyph within the selected gylph list. -b 3: Like -b 2, but width and height are forced to be a multiple of 8.
在“bdfconv”目录下有一个脚本 “test_helvb18.bat”:
bdfconv.exe -v -f 1 -m "32-127" ../bdf/helvB18.bdf -o helvb18_tf.c -n u8g2_font_helvB18_tf -d ../bdf/helvB18.bdftype helvb18_tf.c
参考“test_helvb18.bat”脚本,制作了自己的脚本文件dx_font_create.bat:
bdfconv.exe -v ../bdf/unifont.bdf -b 0 -f 1 -M ../build/dx.map -d ../bdf/7x13.bdf -n u8g2_font_unifont_dx -o u8g2_font_unifont_dx.c
其中相关参数解释为:
../bdf/unifont.bdf ---生成字库的源文件字库,包含所有汉字
../build/dx.map ---需要转换的汉字map表
../bdf/7x13.bdf ---生成字库用的字库文件
u8g2_font_unifont_dx ---生成字库的数组名
u8g2_font_unifont_dx.c ---生成字库的c文件名
根据自定义脚本,需要在目录:
C:\Users\DX\Desktop\TT\New\u8g2-master\u8g2-master\tools\font\build
创建一个自定义字库map表“dx.map”,该map表为copy原有map表chinese1.map并修改所得。
../bdf/unifont.bdf ---使用的源字库文件
../build/dx.map ---需要转换的汉字map表
../bdf/7x13.bdf ---生成字库的字体文件
u8g2_font_unifont_dx ---生成字库数组的名字
u8g2_font_unifont_dx.c ---字库保存的c文件名
32-128,
$5BA2,
$5B9E,
$9A8C,
$5BA4,
$6587,
$5F6C,
$603C,
$4E01,
$9704,
其中dx.map表中每行均为一个自定义汉字的Unicode的编码,具体汉字的Unicode编码可以使用在线Unicode code converter进行查询,网址:
https://r12a.github.io/app-conversion/

按照原有chinese1.map的方式修改自定义map表。

通过cmd命令行方式或运行bat脚本方式均可生成需要的自定义字库的c语言文件。
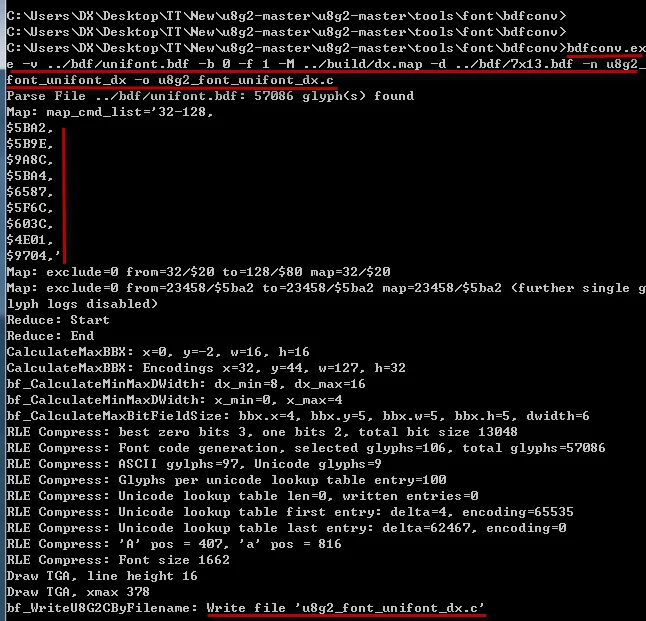
生成的c语言文件内容为:

最后在项目中就可以使用自定义生成的汉字了。

0x05-运行效果
最终在设备上运行的效果:

-
暂无评论